ものすごく今更ですがDellのVenue 8 Proが安く手に入ったので早速モジュールを交換してLTEに対応させてみました
※ モジュール交換には分解を伴い保証の対象外になります
※ モジュール交換に伴いGPSが使用できなくなります
※ 実践する際はくれぐれも自己責任でお願い致します
調べてみるといくつか動作実績のあるモジュールがあるようです
HUAWEI製 ME906J
au系 MVNOで動作報告あり
docomo系 MVNOだと動作しないという報告あり
技適マークあり
Amazon(日本)で取り扱いあり
Dell製 DW5810E
EveryPad Pro(ヤマダ電機版 Venu )などで採用
docomo系 MVNOで動作報告あり
動作に難ありと報告もあるようですがファーム更新後は比較的安定している模様
日本の通販サイトで取り扱いは無く、海外のebayなどで入手する必要あり
モジュールの代金+送料などで1万円ほどを見込む必要あり
富士通製 ANT30MO
au系 MVNOだと動作しないという報告あり
docomo系 MVNOで動作報告あり
技適マークあり
旧ネットワークアクセステクノロジ社の製品
公式ドライバが32bit版しか提供されていない上に
GNSSのMHF4コネクタが独立しており衛星を補足できないようです
Amazon(日本)で3千円ほどで取り扱いされています
今回は安く入手した端末にGPSを使いたいがために高価なモノを選ぶのもアレなのでANT30MOを選択してみました
ちなみにVenue 8 Proは32bit版OSが乗っているので公式ドライバに関しては大丈夫かもしれません
分解・取り付け
本体とモジュールの他にギターピックを一枚用意しておくと良いです
人によっては男らしくマイナスドライバーなどで、こじ開ける方もおられるようですが
ギターピックは身近で手に入りやすく、丈夫な樹脂製で筐体に傷を付けにくいのでオススメです
SDカード、SIMカードは分解前に邪魔にならないように本体から取り除きます
当然ですが本体の電源は確実にOFFにします
どこからでも良いので縁にギターピックを滑りこませて
慎重にスライドすることでパキパキパキ…と本体からバックパネルを浮かせます
接着剤などは使われていないようで、わりとすんなり外せます

モジュールの配線を確認してプラグとモジュールを固定しているネジを外します
ネジで固定されていた箇所から少し持ち上げるようにしてモジュールを引き抜きます

新しいモジュールを差し込みネジ止めします
ケーブルの配線は位置が変わっているため注意が必要です

起動・動作確認
いつもの通りに起動させます
デバイスマネージャを開いてドライバが当たっていない箇所がないか確認します
APNを選択して接続することを確認します
LTEに対応したプランであればしばらく待つとLTEで接続されるはずです
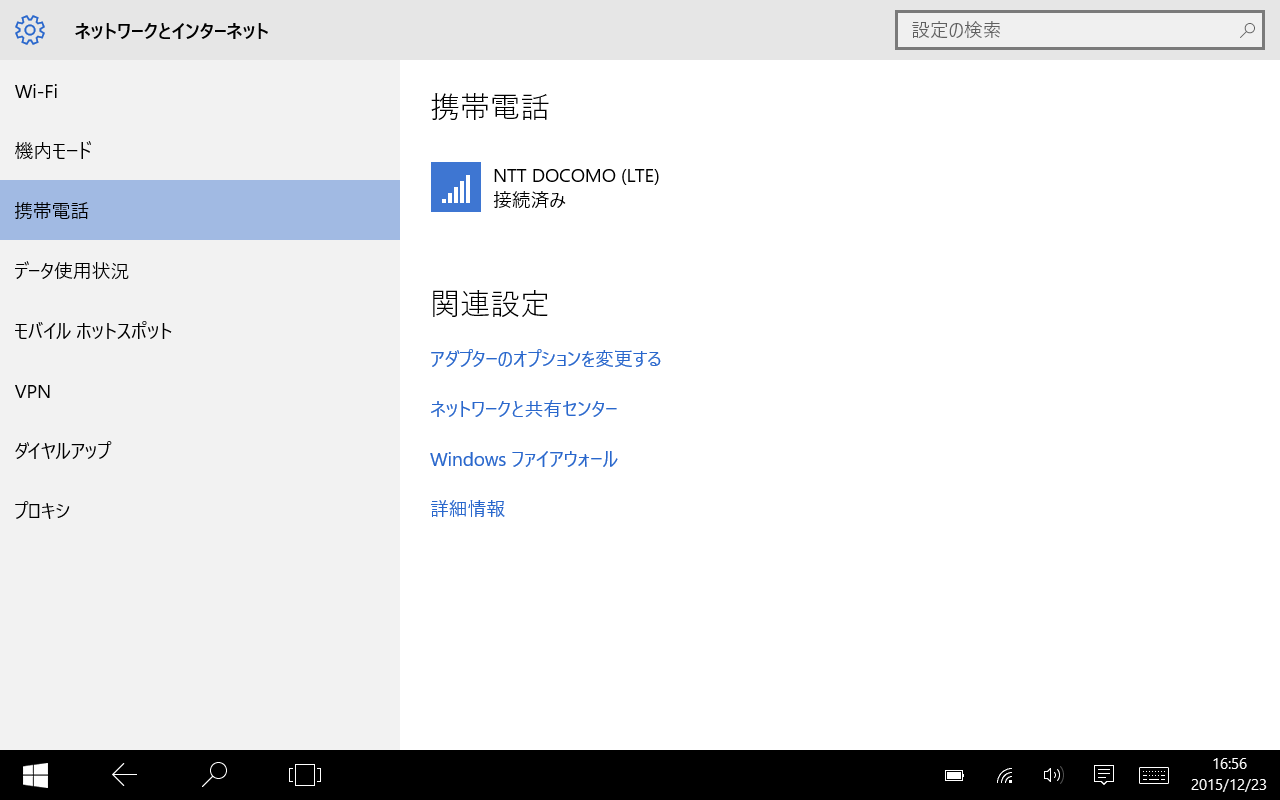
モジュールの製造元がアクセスネットワークテクノロジになっています
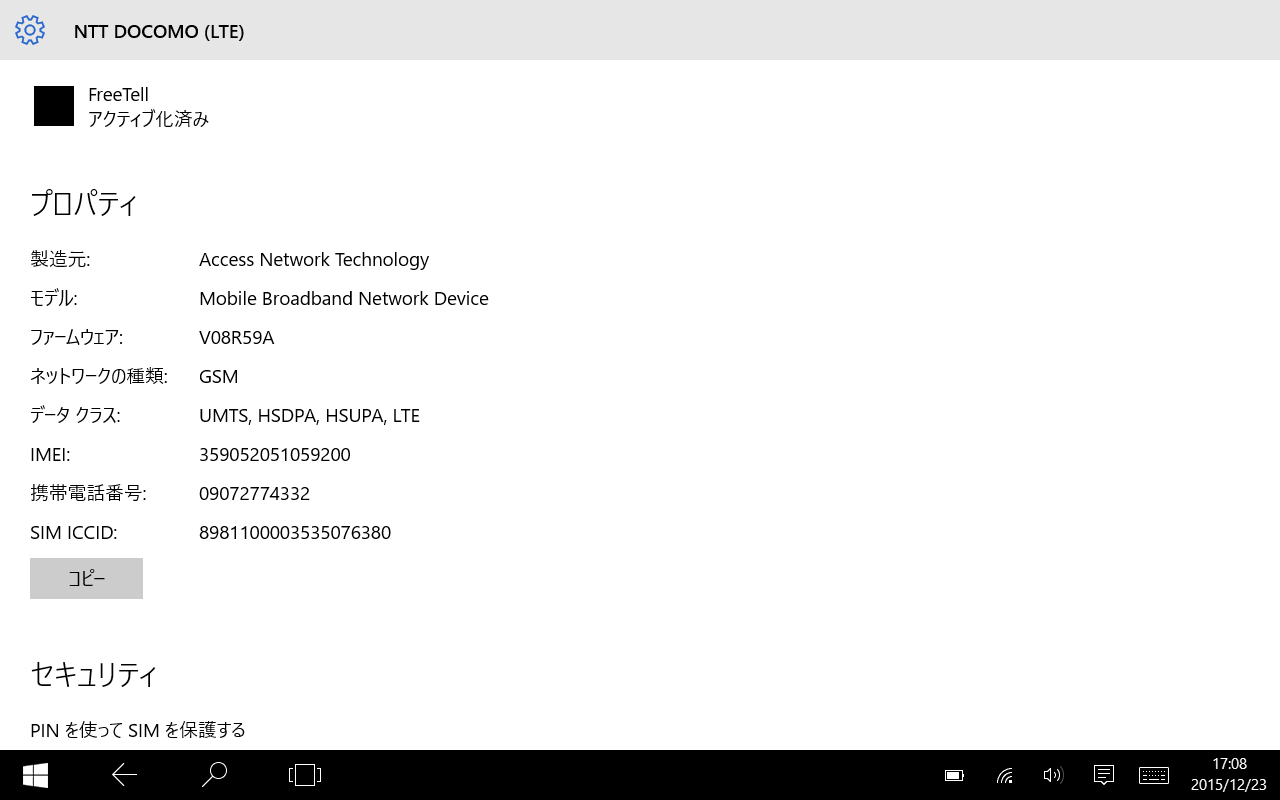
GPSに関してはやはり衛星を補足できていないようです
自分はタブレットでマップを見るシチュエーションが思い浮かばないですが
筐体内にアンテナを追加できそうなスペースがあったので、そのうちアンテナを追加してみるかもしれません
参考サイト
ひまつぶしBlog 2nd Stage: Dell Venue 11 Pro 7140 LTEモデム ANT30MO へ交換で楽々800MHz捕捉
よくわかってないBlog その2 : Huawei ME906J を購入しました(venue 8 pro LTE化) 手持ちのSimカード検証
【Venue 8 Pro】 LTE化に挑戦(中): silent voice にゃ


最近のコメント